
Projekte im Bereich der Datennutzung sind meiner Erfahrung nach sehr vielseitig. Da Anwendungen der Künstlichen Intelligenz individuell auf Unternehmen und deren Datenlage zuzuschneiden sind, ist oft im Voraus nicht klar, welche Use-Cases sinnvoll umsetzbar sind. Da hilft es, wenn man die Herangehensweise an Hand eines über Industriezweige hinweg gültigen Modells beschreiben kann: dem CRIPS-DM. Data Science Consultants leisten dabei vor allem den Brückenschlag zwischen Daten und Geschäftsprozessen. Dieser Beitrag soll einen Überblick zur methodischen Herangehensweise geben.
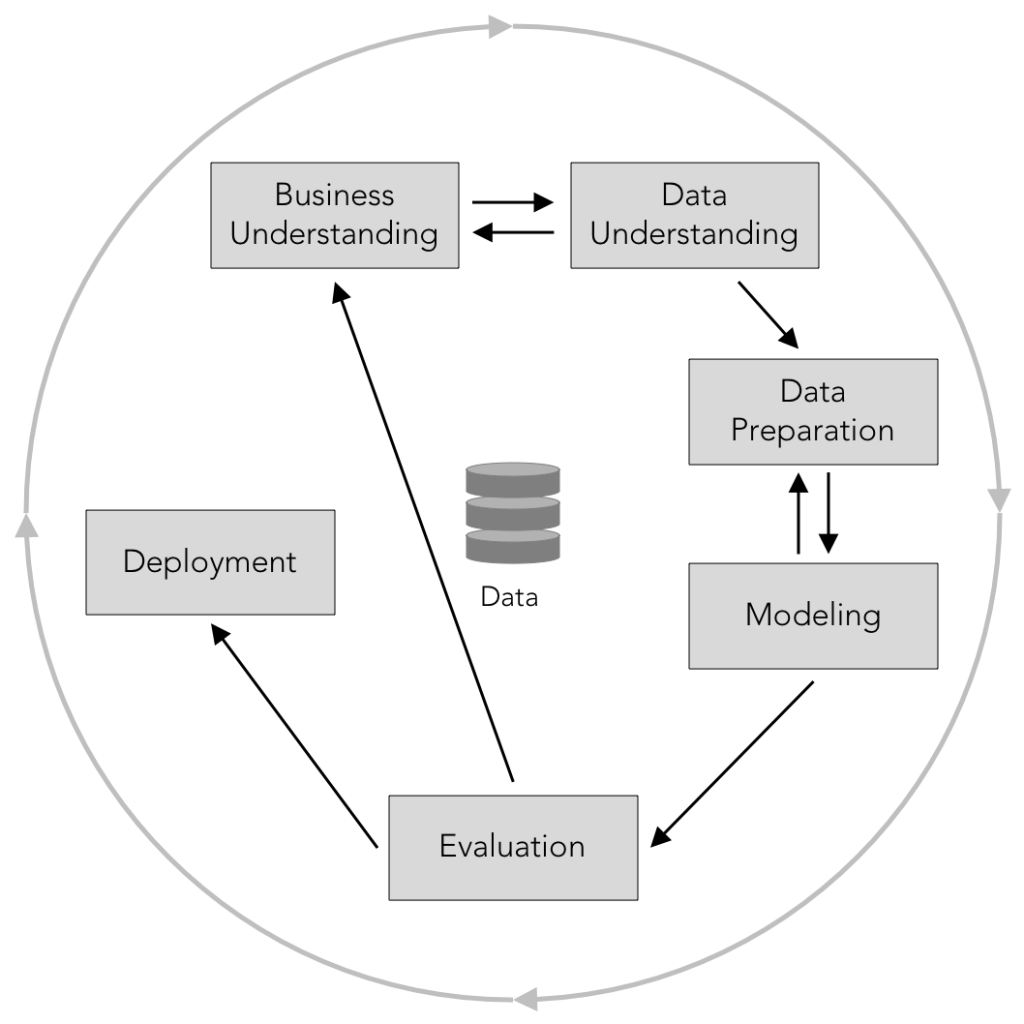
CRIPS-DM
CRIPS-DM steht für „Cross-Industry Standard Process for Data Mining“. Dies beschreibt ein Modell der Herangehensweise für Data Mining und Knowledge Discovery Projekte. Die meisten Experten in dem Bereich arbeiten nach diesem Modell [Marban, 2009]. Der Ansatz erfasst die Essenz dessen was notwendig ist, um erfolgreiche Projekte durchzuführen. Gleichzeitig lässt es sich leicht auf jede Industriebranche anwenden. Die sechs Schritte des CRISP-DM sind: Geschäftsverständnis, Datenverständnis, Datenvorbereitung, Modellierung, Evaluation und Umsetzung. Diese Schritte werden nicht immer in einer linearen Reihenfolge abgearbeitet, wie in der Abbildung oben zu sehen ist. Die einzelnen Schritte erkläre ich im Folgenden (für mehr Details siehe [Shearer, 2000]):
- Geschäftsverständnis
Bevor wir Daten anfassen, ist es wichtig den betriebswirtschaftlichen Zusammenhang zu verstehen, in dem die Daten genutzt werden sollen. Diese Phase beschäftigt sich mit Fragen rund um die Geschäftsziele, Erfolgskriterien, und relevanten Geschäftsprozessen. Außerdem bewerten wir die Situation hinsichtlich der Projektziele und leiten einen ersten Plan ab. Je besser dieser Schritt ausgeführt wird, desto mehr wertvolle Einsichten können wir von den restlichen Schritte erwarten und desto besser wird das Ergebnis sein. - Datenverständnis
Im zweiten Schritt sammeln wir die Daten und entwickeln ein Verständnis für diese. Das erreichen wir, indem wir die Daten sowie die Informationen, die sie enthalten, beschreiben. Auch die Qualität der Daten sollte bewertet werden. Oftmals wird es notwendig sein, mehrfach zu Schritt 1 zurück zu wechseln – solange, bis wir ein klares Bild davon haben, wie die Geschäftsprozesse, Projektziele und Daten zusammenspielen. - Datenvorbereitung
Sobald ein konkreter Anwendungsfall definiert ist, gilt es in diesem Schritt Daten auszuwählen, die für das Projektziel relevant sind, und diese nutzbar zu machen. Dabei müssen auch technische Einschränkungen und Gegebenheiten berücksichtigt werden. Ziel ist es, einen Datensatz zu erstellen, der im Weiteren für das Training und den Test der Modelle verarbeitet werden kann. Die Qualität der Daten kann erhöht werden, indem wir Ausreißer entfernen, uns um fehlende Werte kümmern und den Daten eine geeignete Struktur geben. - Modellierung
In dieser Phase werden zum Beispiel Methoden aus dem maschinellen Lernen angewendet, um ein oder mehrere Modelle aufzusetzen und mit Hilfe der ausgewählten Daten zu trainieren. Hierbei stehen normalerweise mehrere Methoden zu Auswahl. Ziel ist es, die beste zu identifizieren und die freien Parameter zu bestimmen. Dies schließt mit ein, die Qualität des Modells zu testen; zum Beispiel wird die Generalisierbarkeit durch die Fehlerrate auf den Testdaten ermittelt. - Evaluation
Während das Modell selbst im vierten Schritt verifiziert wird, evaluiert dieser Schritt, ob die entwickelte Verarbeitungs-Pipeline und das Model zur geplanten Geschäftsanwendung passen. Nur wenn keine kritischen Aspekte übersehen wurden, kann das Modell im nächsten Schritt in Betrieb genommen werden. Falsche Annahmen aus früheren Phasen führen häufig dazu, dass man erneut zu Schritt 1 gehen muss, also dem Geschäftsverständnis. - Umsetzung
Wenn gezeigt wurde, dass die Anwendung für den realen Geschäftsprozess geeignet ist, dann zielt die Umsetzungsphase darauf ab, die Erkenntnisse des Data Mining Projekts in die täglichen operativen Entscheidungen zu übertragen, d.h. die entwickelten Modelle tatsächlich zu nutzen. In manchen Fällen mag dies ein einfacher Bericht sein, in anderen ist es die Implementierung einer Realzeit-Software, die in die Entscheidungsprozesse der Organisation integriert wird.
Fazit
Um in Data Mining Projekten gute Ergebnisse zu erzielen, ist nicht nur technisches Know-how wichtig. Ein berühmtes Zitat, das manchmal Albert Einstein zugeordnet wird, besagt: „Wenn ich eine Stunde hätte, um die Welt zu retten, würde ich 55 min verwenden, um das Problem zu verstehen und 5 min, um eine Lösung zu finden.“ Anwendungsfälle mit hohem ökonomischen Mehrwert zu definieren ist häufig herausfordernd. Daher sind die Schritte Geschäftsverständnis und Datenverständnis mit besonderer Sorgfalt auszuführen, um ein gutes Zusammenspiel sicher zu stellen. Hier ist Kreativität in Kombination mit systematischem Vorgehen verlangt. Im nächsten Beitrag stelle ich aus meiner praktischen Erfahrung einige wichtige Punkte und Lehren zusammen und hinterlege diese mit Beispielen.
Wie immer freue ich mich über Kommentare, Feedback und Diskussionen: Nehmen Sie hier Kontakt zu mir auf!
Anmerkung: Eine ausführliche englische Version zu diesem Thema ist im Journal of Business Chemistry erschienen und hier zugänglich.
Literatur:
[Marban, 2009] Marbán, Óscar; Mariscal, Gonzalo; and Segovia, Javier. A Data Mining & Knowledge Discovery Process Model. Data Mining and Knowledge Discovery in Real Life Applications, Editors: Julio Ponce and Adem Karahoca, ISBN 978-3-902613-53-0, pp. 438-453, Feb. 2009.
[Shearer, 2000] Shearer, Collins. The CRISP-DM Model: The New Blueprint for Data Mining. Journal of Data Warehousing, vol. 5 (4), pp. 13-22, 2000.




{kind=link}
{kind=link}
{kind=link}
{kind=link}