
Es gibt verschiedene Herangehensweisen an die Nutzung neuer Technologien im Bereich Data Science. In diesem Post erfahren Sie 5 Gründe warum Data Science Projekte scheitern können und welche Voraussetzungen nötig sind, dass Daten im Unternehmen erfolgreich genutzt werden können.
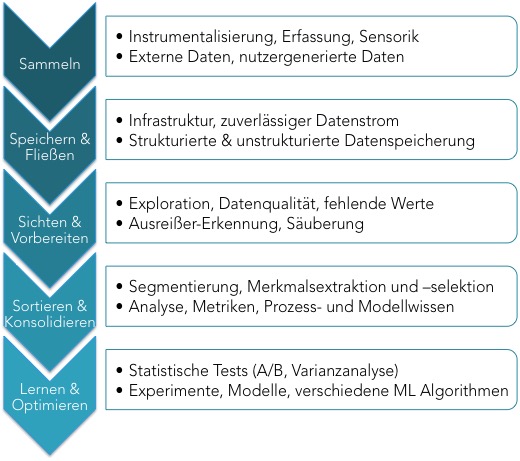
Grundproblem
Der anhaltende Hype um Data Science und Künstliche Intelligenz (KI) verleitet viele Unternehmen dazu, unbedacht oder ohne eine konkrete Strategie zu agieren. Oftmals scheint es wichtiger, die neuen Technologien im Unternehmen zum Einsatz zu bringen, als die Relevanz für das Unternehmen zu bewerten und über einen sinnvollen Weg zum Einsatz der Daten nachzudenken. Dabei wird häufig übersehen, dass Daten nicht einfach ungesichtet, unsortiert und ungefiltert in einen beliebigen Machine Learning (ML) Algorithmus gesteckt werden können.
Auf der Suche nach einer Erklärung und Lösung für diese Situation findet man einiges an Material, das mehr oder weniger pragmatische Voraussetzungen und Herangehensweisen beschreibt. Hier sind 5 Schritte, die – wenn nicht bedacht – eine hohe Wahrscheinlichkeit des Scheiterns mit sich bringen:
Sammlung der Daten
Ein Algorithmus ist nur so gut wie die Daten, auf denen er trainiert wurde. Wenn Daten nicht richtig erfasst werden, führt das zu Problemen, die keine KI mehr reparieren kann. Auch muss sicher gestellt werden, dass die richtigen Daten überhaupt aufgenommen und alle wichtigen Größen messbar gemacht werden.
Ein wichtiger Baustein, um Daten sinnvoll zu nutzen ist daher, nicht nur die vorhandenen Daten anzuschauen, sondern auch die Prozesse und Entscheidungen zu verstehen, die mit den Daten unterstützt werden sollen. Erst dadurch entsteht ein gutes Verständnis für den Nutzen eines Anwendungsfalls und dessen Voraussetzungen für die Automatisierung.
Datenfluss und -speicherung
Wenn die richtigen Daten aufgenommen werden, muss als nächstes der zuverlässige Zugang und die Kompatibilität der Daten gewährleistet werden. Nicht nur die Infrastruktur, sondern auch das Datenformat und die generelle Data-Warehouse-Architektur ist entscheidend. Ob von Sensoren, existierenden Datenbanken, log-Dateien oder manuellen Einträgen: Wie gelangen oder fließen die Daten zu dem Ort der Verwendung? Hier gibt es je nach Szenario verschiedene Herangehensweisen, wobei diese in nicht unerheblichem Maße den operativen Betrieb der Anwendungen beeinflussen.
Datensichtung und Erkundung
Je mehr Zeit man investiert um seine Daten kennenzulernen, je größer ist die Wahrscheinlichkeit einer erfolgreichen Implementierung – das haben Witten und Frank schon vor knapp 20 Jahren erkannt und es gilt mit steigenden Datenmengen heute um so mehr. Sind die Daten vollständig? Gibt es fehlende Werte? Wenn ja, wie häufig? Wie zuverlässig sind Datenquellen? Gibt es Ausreißer und wie geht man mit ihnen um?
Dieser Schritt wird erfahrungsgemäß viel zu sehr vernachlässigt, obwohl hier ein ganz erhebliches Potential sowohl für Fehler als auch für die Sicherung des Erfolgs liegt.
Konsolidierung der Daten
Als wichtigen Schritt vor dem eigentlichen Modelltraining erfolgt die Segmentierung und Konsolidierung der Daten. Hier kann der Wert der Daten mit verschiedenen Methoden erhöht werden und wertvolles Prozesswissen eingebracht werden, um so die Menge der benötigten Daten zu reduzieren. Die Ergebnisse der Sichtung fließen in diesen Schritt ein, der Vorverarbeitung (z.B. Filterung), Segmentierung der Daten (insbesondere bei Zeitreihen), Merkmalsextraktion (Feature Engineering) und Merkmalsselektion beinhaltet. Gerade bei kleineren Datensätzen ist dieser Schritt enorm wichtig, um zuverlässige und robuste Modelle zu generieren.
Modelle lernen und optimieren
Die Wahl des Modells ist entscheidend für den Erfolg. Leider wird durch die omnipräsenten Schlagwörter wie Deep Learning (eine spezielle Form von künstlichen Neuronalen Netzen) und leicht zugänglichen Open-Source Paketen wie TensorFlow manchmal der Eindruck erzeugt, dass man einfach alle vorhandenen Daten in ein Black-Box Modell füttert – in der Hoffnung auf verlässliche und generalisierbare Ergebnisse. Auch wenn das in einigen Fällen tatsächlich funktionieren kann, z.B. in der komplexen Bildverarbeitung mit vorhandenen großen Datenmengen, so sind für die meisten geschäftsrelevanten Use Cases nicht ausreichend Daten vorhanden, um solche One-Size-Fits-All Ansätze zu verwenden. Eine differenzierte Modellauswahl ist nötig.
Um die Gefahr des “Overfittings” (d.h. die übermäßige Spezialisierung des Modells auf den Trainings-Datensatz) zu vermeiden ist die Evaluierung des Modells durch Testdaten vorzunehmen. Auch die prototypische Erprobung des Modells im Zielprozess ist ein wichtiger Schritt, bevor die endgültige Applikation in Betrieb genommen wird.
Folgen für die Herangehensweise
Eine genaue Analyse der vorhandenen Daten und deren nützliche Verwendung in Geschäftsprozessen ist eine wichtige Voraussetzung für die Erarbeitung einer Digitalstrategie. Auch ist ein besonderes Augenmerk bei Anwendungen immer auf die Interaktion von Mensch und Maschine zu richten, denn der Mensch wird auch weiterhin eine bedeutende Rolle spielen. Das heißt, den Menschen in seinem Handeln komplementär mit der Technologie zu ergänzen und zu fördern.
Meine eigene Herangehensweise ist stark Use Case basiert. Das bringt den Vorteil, dass alle oben aufgeführten Schritte von Anfang an mit berücksichtigt und auf die Anwendung zugeschnitten werden können. Erst wenn diese 5 Schritte beachtet werden, kann eine KI oder Machine Learning Anwendung wirklich erfolgreich sein.
Über Feedback, Fragen, Diskussionen und Anregungen freue ich mich immer: Hier finden Sie meine Kontaktdaten.




{kind=link}
{kind=link}
{kind=link}
{kind=link}